Odoc and OCaml Notebooks
As the chief maintainer of OCaml's odoc, I'm required to think hard about its future. What impact will advances in agentic programming, collaborative literate coding, and the dramatic increase in web platform capabilities through wasm and WebGPU have — both on how odoc works and on how we develop it?
I find the best way to explore these topics is to build something, so I've gone all-in on Claude and used it to rewrite my website with all new odoc-built dune-friendly client-side Jupyter-style notebooks as an integral part of it! Those of you that have read this blog for a while will know I've been tinkering with notebooks for a year or so now, and I've had an extremely long-running fascination with scientific visualisation in the browser, but I really wanted to push this hard and see how adding Claude into the mix would work out.
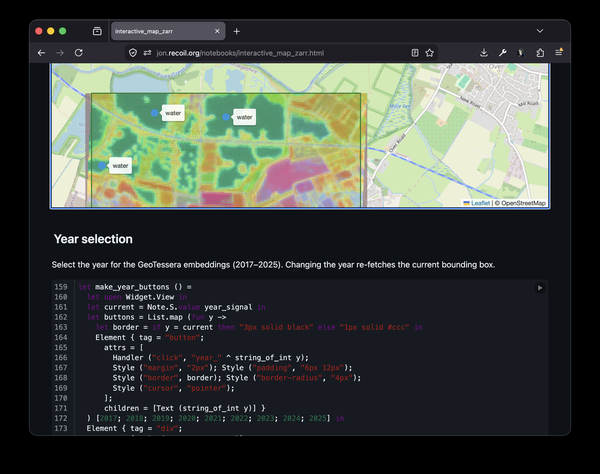
It's very helpful to have a specific use-case in mind for the notebooks to guide the exploratory work. This was an easy choice: My group has been spending a lot of time recently on TESSERA, and this provided a perfect demonstration for the notebooks, as it heavily relies upon being able to use interactive maps to choose areas of interest, and to visualise the embeddings and picture the output as map overlays. As well as being a fine motivating example, it's also given me an excellent reason to learn more about geospatial coding, which I've been wanting to do for a while. The specific example I chose to port required adding support for various interactive widgets in the browser-based programming environment, where I'd only previously been able to render static rich content.
Also, inspired by my colleagues' experiences with notebooks, I've been experimenting with the execution model and interactivity to ensure reproducibility, and considering the implications of the FAIR (findability, accessibility, interoperability, reusability) principles of the Fairground paper, which provides a perfect framework of requirements for the odoc notebooks. These more ambitious goals meant a more ambitious approach to the changes.
Despite this, with this rewrite I've thought much harder to ensure that what I've done will fit into the upstream ecosystem. It's now all built using dune with the standard rules I've already started upstreaming, and by using plugins with odoc I've minimised the necessary changes to the core of odoc. While there's work to be done, there's a far clearer path to ensuring this work can be used by everyone.
I've chosen to use OxCaml both for the build environment and the runtime environment on the web. While the choice doesn't make a huge difference in the browser, a longer-term vision is to have a choice of execution environments, and oxcaml for running high-performance numerical code makes a lot of sense.
The implementation work can roughly be split into three parts: Infrastructure and Odoc, the Js_top_worker and widgets libraries, and the actual TESSERA code. Then I've got some thoughts on the implications of the experience, for open source development in general and odoc and the notebooks specifically.
Infrastructure and Odoc
In order to have a fast build cycle I needed an incremental build. Last year I wrote up my experiences writing the dune rules for odoc with Claude. I opened the PR, representing a "feature complete" replacement for the current rules, in that it can completely replace what's in dune now, but doesn't extend the rules for the new features of odoc. Since then we've merged the first part of it, and happily my colleague Paul-Elliot is back from his brief sabbatical working on slipshow to work on getting the rest of it merged.
To support my goals though, I've had to extend the rules by quite a lot from that initial work. I've got support for assets so I can put images on my blog posts, support for source rendering so that you can see the code I'm using. There's markdown output for Claude to consume, and sherlodoc native support so you (or your agent) can run sherlodoc queries on the command line. The prefix for all output is configurable, so that I was able to put everything dune built under "/reference", and pass arbitrary options to the various invocations of odoc so that I could specify global defaults like the Javascript toplevel worker and opam repository to use in my notebooks. We've also now got smarter rules that don't pull in as many dependencies as the current PR, so that I didn't have to install any extra packages I wasn't using just to build my own docs.
Most of these changes will be useful to the wider OCaml community, so it makes sense to try to upstream them. They're also fairly orthogonal to each other, and are obviously dependent on the original PR, and hence they can be made as independent PRs once the big one has been merged.
Odoc
OxCaml support for odoc was contributed by Luke Maurer early on after OxCaml was released. However, this only fixed the build of odoc, it didn't give it any mode or layouts, nor any of the other new features of OxCaml. I asked Claude to look through the way the toplevel prints these annotations and port them to odoc, and that's been implemented on this site. For example, see Base.Uniform_array.length - you can see there the portable, local and contended annotations on the type. If you click on the source link, you'll see I also added some improvements to the source rendering - there are many more links now and we've got the ability to link to source from doc comments and mlds.

One of the earliest things I did was to give Odoc a new plugin system that has been hugely enabling for building the new features. I'm using dune's site feature for the plugins, which really "just worked". It was very easy both to add the feature to odoc and to create the plugins themselves. Building a whole variety of plugins has also been very useful in testing the shape of the plugin API, and I've made numerous changes to it as I've built them and they expose various problems.
The plugins are activiated in a few different ways. The first is to allow custom tags, e.g. @foobar <content>, a feature of ocamldoc that odoc didn't previously support. The plugin registers handlers for a particular set of tags, and when odoc encounters that tag it calls the plugin to find out what should be rendered. The second way is for plugins to handle particular source-code blocks, e.g. {@baz k1=v1 k2=v2[ ... ]}. Once again when odoc encounters a matching block it gets passed to the plugin to determine what should be rendered.
Let's take a brief look through the plugins I've made.
Admonitions
This is a feature we've wanted to add to odoc for a while - and we have a design sketched out for it.
This is more-or-less a throwaway plugin as we'll be doing this "properly" and won't need it. It made for a nice first test though and the functionality is useful and quite important. I've been using it to mark the truly agent-coded libraries where I've not seen the code at all, as opposed to those where I've been far more involved in the changes and I'm slightly more confident in how they work.
The code for this is on tangled, and is a good example of a very simple plugin.
Diagrams
I've got 3 diagramming plugins - odoc-mermaid-extension, odoc-msc-extension and odoc-dot-extension. These were particularly useful in understanding the need to determine the lifecycle of any javascript glue that's required, especially when we're dynamically loading pages like ocaml.org does. And in fact I've put the Mermaid extension to use documenting the issues in the extensions documentation.
Here's a diagram showing the dependencies of my TESSERA libraries:
graph LR
tessera-zarr --> tessera-geotessera
tessera-zarr --> tessera-linalg
tessera-zarr --> zarr-v3
tessera-zarr-jsoo --> tessera-zarr
tessera-zarr-jsoo --> zarr-v3
tessera-geotessera --> tessera-linalg
tessera-geotessera --> tessera-npy
tessera-geotessera-jsoo --> tessera-geotessera
tessera-tfjs --> tessera-linalg
tessera-viz --> tessera-linalg
tessera-viz-jsoo --> tessera-viz
zarr-v3-unix --> zarr-v3Interactive pages (notebooks)
My previous efforts at creating notebooks involved a separate pipeline to build them, but with this plugin it became trivial to have them built as part of the normal 'dune build' process.
The odoc-interactive-extension uses art-w's x-ocaml to add interactivity to the mld files. The plugin itself is rather simple, really just finding marked ocaml code blocks and outputting an <x-ocaml> element into the HTML. The metadata in the code block is translated directly into attributes in the x-ocaml tag allowing arbitrary parameters to be passed.
I have some more detail on x-ocaml and js_top_worker later in this post.
Scrollycode
The odoc-scrollycode-extension is based on Rodrigo Pombo's work and similar scroll-linked tutorial sites like MLU's decision trees page. I initially had Claude come up with a sketch to show it working, complete with Merlin integration so that types-on-hover work:
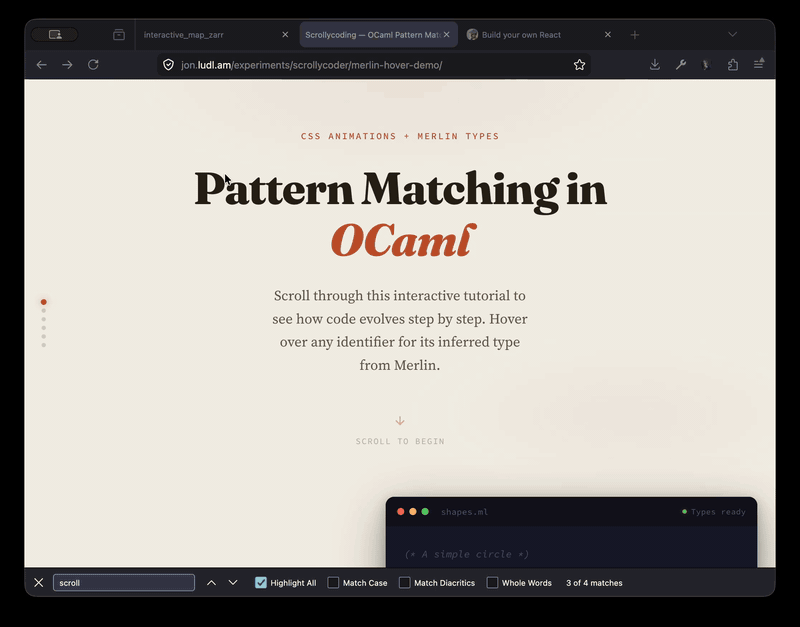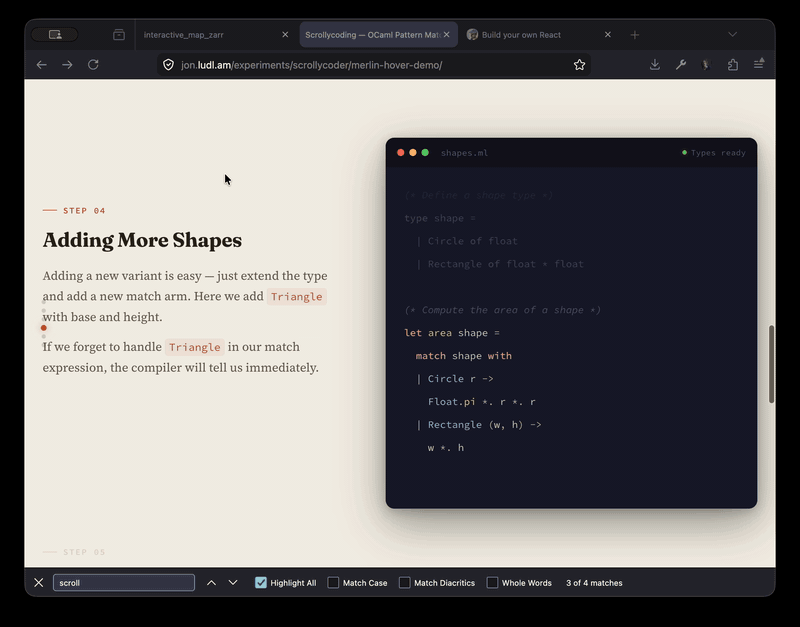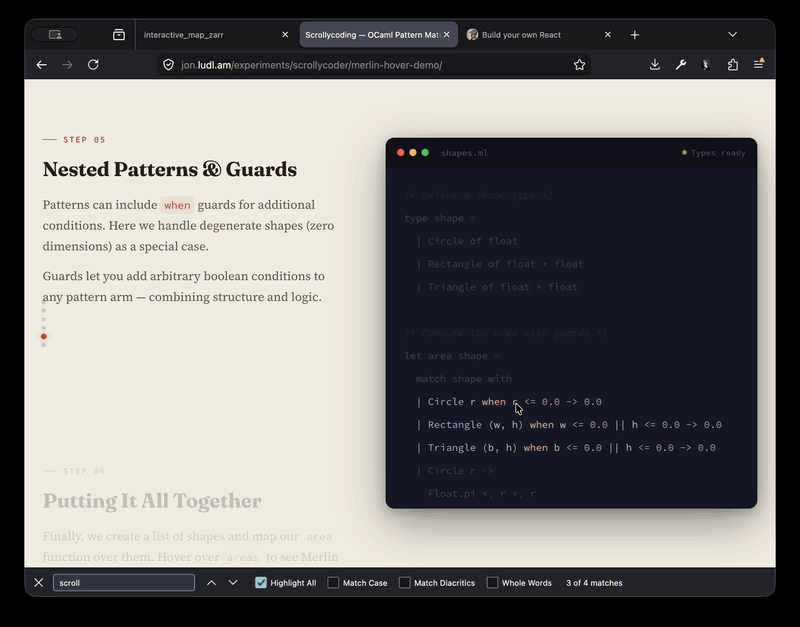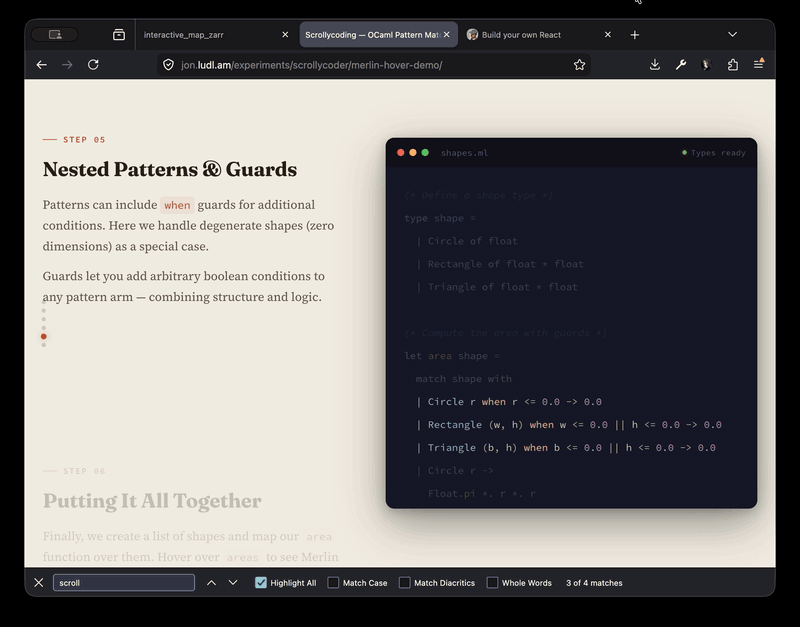
With that as "proof-of-concept" I then built a new odoc plugin so that you can just insert special markup in the source and you get lovely animated tutorials:
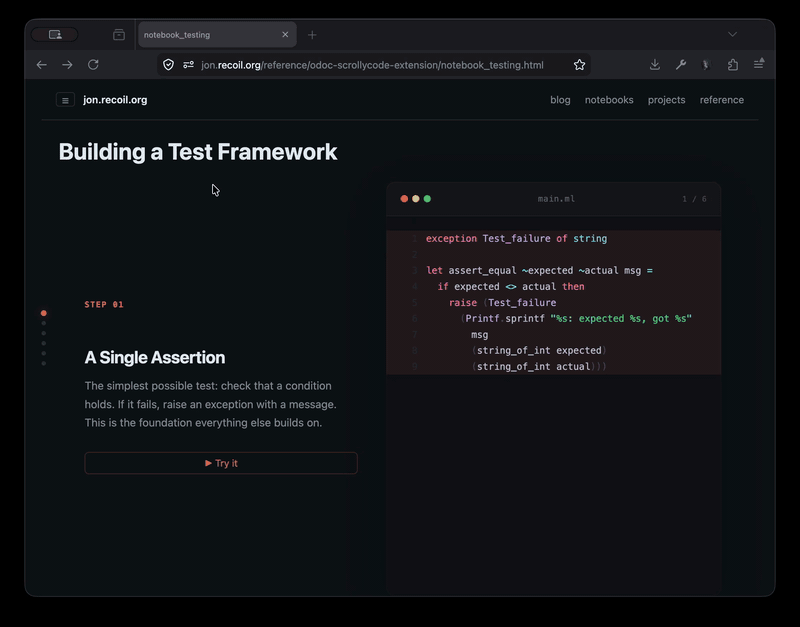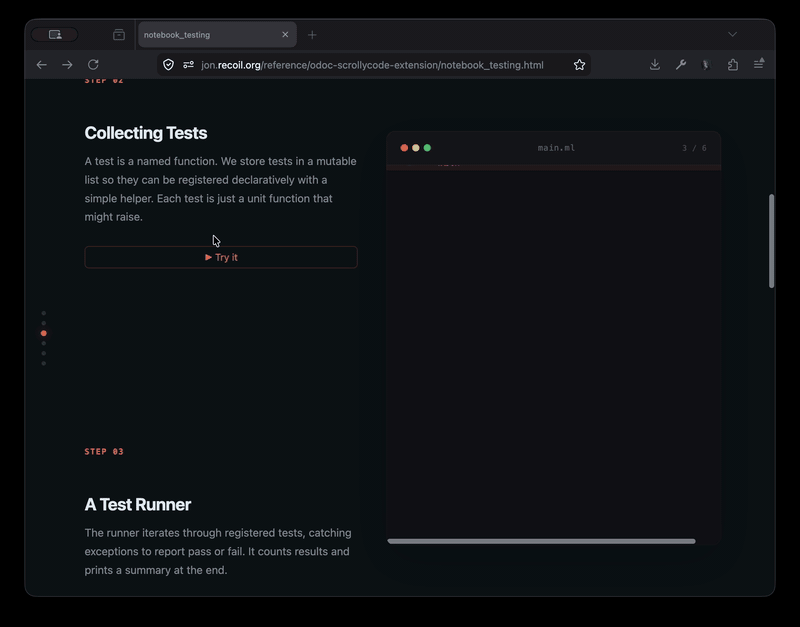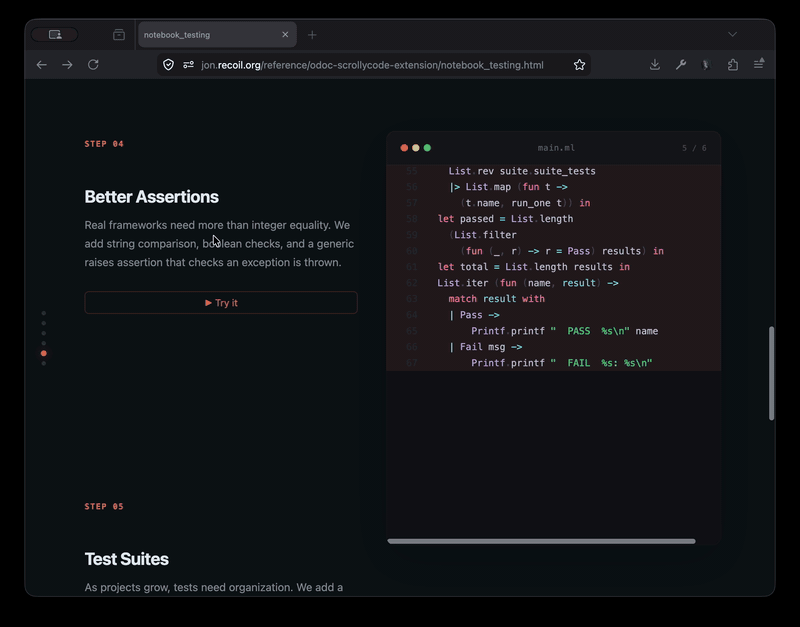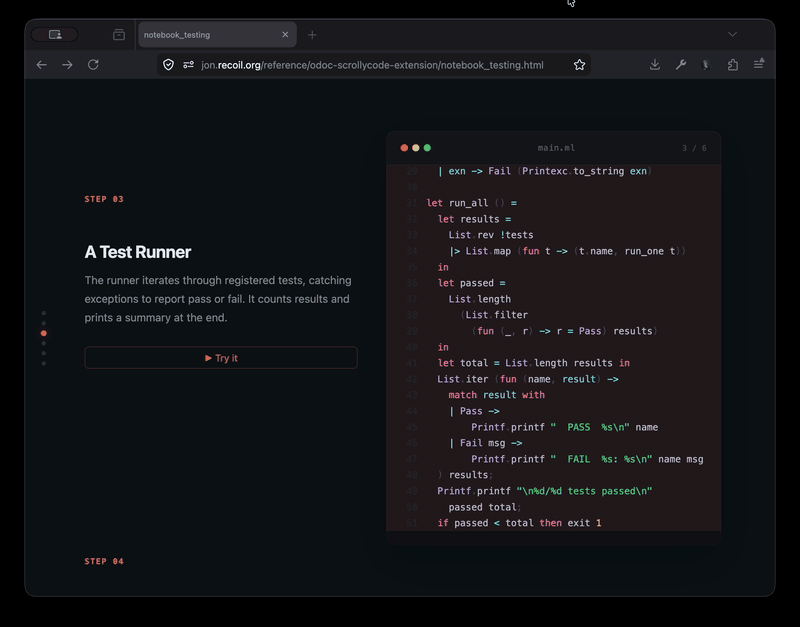
The screen recording above is from one of the test pages, and currently shows only the incremental building of a module. Rather more interesting is something like Rodrigo's original build your own react page that showcases modification of the source as you scroll though, where it starts with a very simple program and progressively builds in more features. I'd like to extend my plugin to support this soon.
HTML shells
The "traditional" way that you embed odoc output into another webpage, like ocaml.org does, is to output JSON. This works well where you've got a smart server that can read the JSON and render it on demand, but when you're trying to build a static website like the dune rules produce, it's rather less convenient.
The HTML shells extension is part of the odoc plugin system, and allows you to swap out the default HTML renderer for another completely customisable one. I have two plugins that use this system:
- odoc-docsite which produces a more modern SPA-style site.
- jons-shell which produces this website.
The advantage of using these is that it doesn't affect the flow of the documentation pipeline, so there are no changes required to the dune rules for it to produce a very different output. You just install the plugin, add the '--shell <...>' to the dune file or dune-workspace file at the root of your repository, and run dune build @doc.
The second of these plugins is a good example of a bit more of an involved one - see the source code.
X-OCaml and Js_top_worker
x-ocaml is art-w's excellent tool to to add interactivity to any web page. It works by registering a new HTML element x-ocaml that can be used like any normal HTML element, producing a Codemirror-backed editor with a "run" button that will execute your code in your browser using a web worker.
In order to use OxCaml in my notebooks, I needed a stronger separation between the code running in the browser context and the "execution engine" running in the web worker. I switched from Marshal for the communications layer to JSON, as marshal is incompatible between OxCaml and OCaml, which meant that a single frontend implementation can now talk to both OxCaml and OCaml workers running in the web worker.
My fork is using js_top_worker as the library and tool that's used to manage the javascript toplevels. The goal of the tool is to use it to have toplevels or interactive notebooks for every package in opam-repostiory, so it's important that it's careful about what can be cached. As such, the design is that there's a single toplevel worker, and libraries can be dynamically loaded in via #require, just like the standard toplevel. Each library is compile from a cma to a cma.js, and the cmis are also dynamically fetched as they're needed. The worker, the cma.js files and cmis are then hosted alongside META files and an index.
The Toplevel index file:
{"meta_files":
[ "lib/yojson/META",
"lib/uutf/META",
"lib/uri/META",
...
"lib/js_top_worker-rpc/META"
],
"compiler":
{"worker_url": "worker.js"}
}One important new feature of js_top_worker that I've built for the notebooks is the ability to use interactive widgets. This requires two-way communications between the main javascript thread and the web-worker backend as we want to be able to trigger changes from both sides. Rather than hard-coding all the widgets that can be made, the design allows new ones using standard OCaml libraries, so you can dynamically load in the widgets you require into your notebook, or even write new widgets there directly.
Each widget either has direct DOM callbacks, or injects some javascript glue code into the frontend, which then communicates between back and frontend using JSON. This layer is mostly "stringly typed" using the widget library. On top of that you can then build more strongly typed libraries like the Leaflet library that give a more pleasant interface. Communications happen in both directions, so code can cause widgets to change, and interaction with the widgets can cause code to execute.
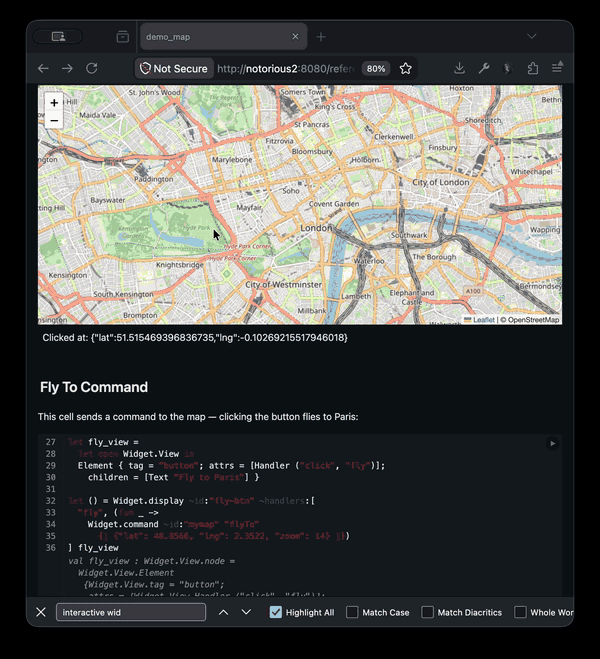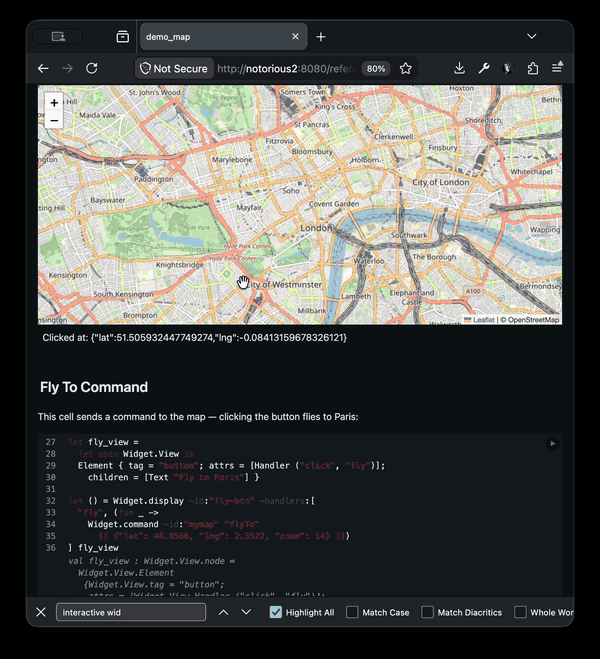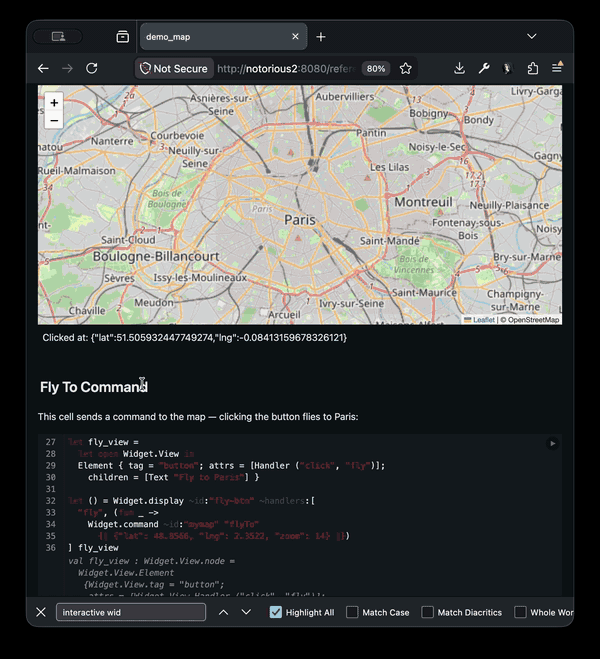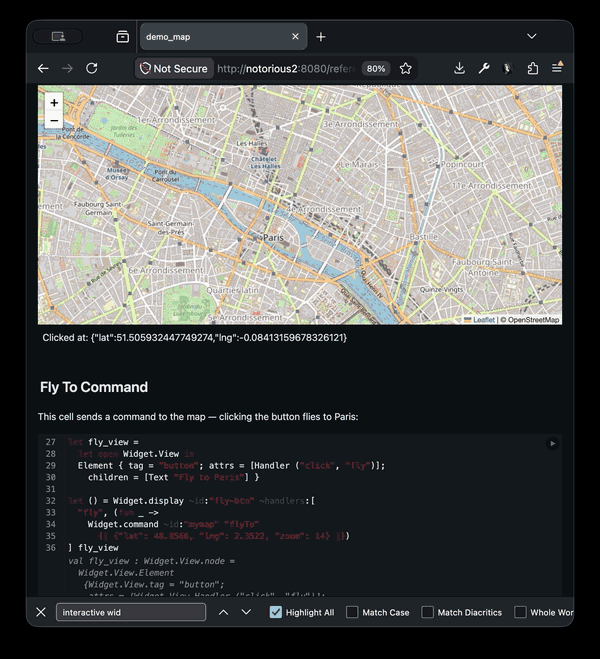
Try the demo out yourself here.
Execution model
My colleague Michael Dales wrote about the challenges of balancing interactivity and incremental computation in notebooks, and his post he settled on Marimo. The approach that Marimo takes is to analyse the code and build a dependency graph so that as values are adjusted, any affected part of the computation can be re-evaluated. You can then create values with UI elements attached, and the whole experience is very pleasant.
The "usual" approach to this sort of UI interaction in OCaml is to use an incremental library of some sort, like Jane Street's Bonsai or React. In this way we can build the dependency graph and re-evaluation semantics within the language. In these examples, I've used Note. The interesting wrinkle in this work is that because all interactions are being mediated by js_top_worker, we've got a single place where we could record the interactions that have happened, and then potentially "play them back".
With support for OxCaml, widgets and dynamic library loading, and integration into the docs pipeline via the odoc interactive plugin, it was time to create a real-world notebook to verify that it could be used to do "proper science"!
TESSERA notebooks
One of the most exciting things to come out of our group recently has been TESSERA, a pixel-wise Earth observation foundation model. The code and demos for this are mostly in Python, particularly using Jupyter notebooks. This provided me with an excellent stress test that tied together many of the strands of this work and validated that they could be used together to build something useful. A simple python notebook showing the basic workflow already existed, so I decided to port it to OxCaml, and more specifically to make an odoc notebook. You can run the resulting OxCaml notebook in your own browser, with no server required at all.
The notebook works by first presenting a map, and asking the user to select an area to download the TESSERA embeddings. Once we've got the 128-dimensional per-pixel values, we then need to display them. Rather than simply picking 3 dimensions as our RGB values, we do a PCA computation to choose some vectors for our colours. This is then overlaid on the map by first turning it into a .png, then encoding it as a base64 data URL, and passing it to the frontend to overlay on the map. The user then picks some points on the map, categorising them into arbitrary groups. We then run a knn classifier over the whole downloaded area and finally overlay that image.
I struggled a little with co-ordinate systems, mostly because the distortion if you dont map is fairly small, so it looks pretty good. However, you can see clearly on this image that the A14 (the red road at the bottom left) is a little bit off:
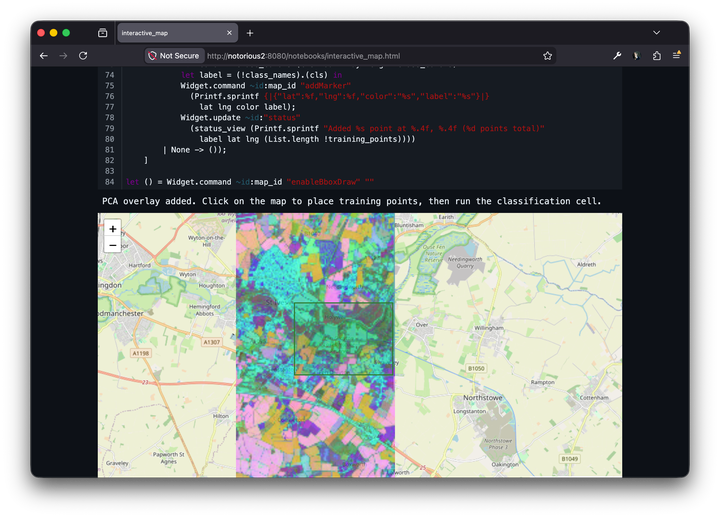
In the newer notebook where I do the remapping correctly, it matches much better. You can see the remapping by looking at the left and right sides of the overlay, where they're no longer quite vertical.
This version uses the Numpy interface to TESSERA, which downloads the embeddings in quite large (100M) chunks. While it was nice that this worked, it meant it was quite slow to see anything actually happening. I then switched to using the Zarr_v3 format, which is far more efficient, using range requests, compression and better encoding to reduce the bandwidth requirements. This version is here.
This really demonstrated that the approaches I've made with the various different strands of work can all be knitted together in a very useful way, allowing us to bring the strong type system of OCaml together with the ubiquitous runtime of the browser, and using the power of WebGPU to run calculations that can help to change our world for the better.
Implications
I've written (or caused to be written) a lot of code for this project. It's all "open source" in that the code is available, though this is the very minimalist sense of the term. I've both modified other people's code, and written other things from scratch, and pushed everything publicly on the repostiory. It's been a fundamentally different experience than everything I've done in the past 25 years or so of OSS development.
Traditionally with open source software, most people never change the code. The vast majority of people take the code, run it, use it, and get on with their lives, grateful to varying degrees to the authors. A much smaller number of people will make changes to the code. This requires an enormous investment of effort, firstly in learning to code at all and then learning the specific codebase sufficiently well to make a change. A small subset of these people go to the additional effort of trying to upstream the code, and open a PR. At this point, the maintainers of the code now also need to put in a lot of effort to review what's been sent, and engage with the contributor to address any issues with the code. So it's hard work. Why do people bother?
This process is helpful to the contributor as maintaining patches on an open source project is not only work, but unpredictable work. Upstream changes can require you to have to fix your modifications at any time, and those fixes might be anywhere from trivial to completely impossible. Getting your patch upstreamed means that there's a much better chance that whatever it is that was fixed or improved remains that way without further effort.
On the part of the maintainer, the effort of reviewing and interacting with the contributor will hopefully both improve the code, but also effectively enlarge your workforce as the contributor learns more about the project. The more people who know about the project, the easier maintenance becomes.
LLMs have totally upset the balance of these motivations. From the contributor's perspective, the effort now required to maintain your own fork of a project is much smaller, as you don't need to learn the codebase anywhere near as deeply, and you don't have to worry anywhere near as much about maintaining your fork as upstream changes. So it's both easier for there to be code changes, and it's less rewarding to try and upstream them. From the perspective of the maintainer, there may be many more low quality pull requests, and in many cases there will be limited value in trying to cultivate new contributors as the LLMs can't learn directly from the feedback, and the humans guiding the LLMs will know much less about the project as they haven't needed to in order to make the PR.
Where these adjusted values will lead is very hard to predict. Empirically though, I find that I've made few PRs over the last few months, but I've amassed a lot of new repositories and forks of existing repos, and it's been very easy to slip into this mode of working. The effect on non-programmers hasn't begun to happen really, but there will be an effect and it will be profound. I'll know when that moment arrives when my artist-rather-than-scientist family members are using LLMs to alter code - which to them will just be the latest change in MacOS that's happened, but I'll know what's going on.
Attribution
My early purely-agentic commits were all authored by me and co-authored by Claude. This is a lie. Morally, I found I couldn't carry on like this so I've switched now to having the commits authored by "Jon's Agent". My plan is to rewrite the author when I've gone through it line by line, and even then, I feel that Claude ought to be marked as Author and I should just be adding my "Reviewed-by" line onto it. In either case, for a pull request to be made the human in the loop has the responsibility to justify the changes, and therefore has to be totally familiar with both the changes and the code being changed. I'm not at all fundamentally opposed to having LLMs involved in the process of making changes to open source code, but in my experience so far, there's a huge amount of effort that needs to go into it even after you've got working code and tests. I've tested the waters with my dune PR, and have merged a simple bugfix or two to odoc. Even these one-liners needed careful thought and attention before I felt I could make a PR though, and the dune PR took much more effort than that.
Bug-discovery
One thing that I've found tremendously useful is narrowing down bugs. Armed with a repro, setting Claude off to track down issues has been a wonderful time saver. Additionally, asking it to explain the issue in detail with links to the source is very handy indeed. It's not, however, able to discover all bugs, even with a lot of time. When working on the fix for a particularly nasty bug, I found that with the patch applied we'd get a different error somewhere deep in some of Jane Street's async ecosystem. I had a good suspicion of what the problem was given the changes that had been made already, as the code I had altered had an analogue elsewhere in the codebase that hadn't been fixed, so I thought this would be quite a good test for Claude. I gave it lots of hints, but it flailed at the problem for several hours, often giving up, sometimes blaming the OxCaml compiler, and sometimes upstream OCaml. In the end I couldn't get Claude to make useful progress so I implemented what I thought should be the fix and indeed the problem went away. So there are clearly classes of bugs that are still beyond Claude's capabilities to understand, which isn't an unexpected result.
API boundaries
I've found it very helpful to have API boundaries to help structure the code that Claude has been producing. Anil has long been enthusiastically pushing the idea that we should write the mli files first, which constrain what types and values are available between the modules. We can then write tests that target these interfaces, and then adjust them where the tests have shown them to be inelegant or downright unusable. We can then write the implementations and watch the tests start to pass. A particularly interesting example of this is the odoc plugin interface. The experience of writing several very different plugins that all extended odoc in different directions was very helpful, and I adjusted the interface quite a few times. I also adjusted the documentation, where qualities about how the interface behaved that weren't obvious from the types could be carefully noted, for example how scripts might be made to behave correctly when the odoc pages were in an SPA shell. Far too often in the OCaml community we've relied just on types and modules as documentation for our libraries, and this is rarely enough.
Failure modes
When I was working on the dune rules, I made the mistake of going too long without giving Claude some architectural constraints, and I ended up with a Big Ball of Code that I then had to spend time unpicking and teasing apart into sensible looking modules. I had rather hopefully believed this to be a Claude Opus pre-4.5 problem, but I still hit this recently when adding a new feature, when it just added vast amounts of code to one file to implement it, and the code was all very unstructured and unsatisfactory. This was despite going through a design process where we went through the goals, the use cases and desired features, but crucially, not at the level of the code.
Another failure mode I observed was my failure. It's very easy, and very tempting, to get your agent to do the next neat thing on the roadmap. Especially when you've just spent a while going through the design and planning for the previous feature and Claude has got started on it. The problem is that this can generate a large amount of code that kind-of-works but has a bunch of bugs, which can end up costing a lot more time and effort. The cost of starting the agent going is much smaller than the cost of wading through the results, and it's quite easy to end up drowning under a load of very interesting and partly cool half results. I'm very much reminded of Dr Ian Malcolm's words from Jurassic Park: "your scientists were so preoccupied with whether or not they could, they didn't stop to think if they should."
What's next?
In the more immediate future though, perhaps with my odoc-maintainer hat on, I still want to make sure that I extract the useful parts of what I've done and get them upstreamed. While everything I've done is all open source and published, there's a lot of work I need to do so that others in the community will benefit from my changes. While it's technically possible to add my opam-repo to your switch, and install my versions of odoc, dune, and my various plugins, I don't think many people are actually going to do that. Worse than that, people might get their agents to just grab the source and mutate it further, just diluting the efforts going into it.
Fortunately I've been talking with Paul Elliot, who has volunteered to shepherd the dune PR through to completion. I'll be working with him on this of course, but I'm hoping he'll be doing the lion's share of the work.
The OxCaml work will be taken on by art-w who's already done an excellent job getting Luke Maurer's patches into shape and PR'd to ocaml/odoc.
We'll be having a forward-looking odoc meeting on the 8th April to think about the roadmap for odoc, and I'm confident that my work will help us in the discussions of what directions odoc will be heading in over the next year or so. Whilst the bigger picture of how the world is evolving plays out we need to at least carry on maintaining the community software, and use LLMs wisely and carefully as another tool in our toolbox to help us keep the code as useful and bug free as possible.